Overfitting Data
There is a network that overfits the XOR function and other types of data.
In the previous post, I showed that using gradient descent would find weights such that the loss function obtained a local minimum instead of a global minimum. In the model that I proposed, there was only one hidden layer and two units in the hidden layer. Further, I purposefully chose the initial weights in order to obtain a close approximation of the true weights (weights that result in the squared loss function being globally minimized or zero).
In this post, I investigate deeper neural networks (i.e. more hidden layers and more units in each layer) with random initial weights to approximate (i.e. overfit) the XOR function. The framework created in this investigation will likely help in creating networks to overfit other problems. Once a large enough network can overfit some data, I can then work on determining the optimal number of iterations to run in order to decrease the validation error as much as possible (i.e. early stopping). In this post, I use python’s Pytorch package to make the computations needed for backpropagation.
Model of a Deep Neural Network
Let the input matrix be , output vector be , and the matrix (or vector) weights and vector biases in layer be and , respectively. Let the input to layer be denoted as where . For any layer , given the input dimension , output dimension (note that if and is the dimension of the final output), and input , the Pytorch class torch.nn.Linear initializes the weights and biases to randomly selected values from the uniform distribution and applies the transformation . Note that can be interpreted as the input to the activation function. The function torch.relu applies the function element-wise. Define the output from the activation function for layer to be , and define the prediction as . Suppose that the loss function is .
Further suppose that the learning rate in this model is 0.01. The Pytorch class torch.optim.SGD will compute and for all and , where is the total number of iterations.
Example of Overfitting the XOR Function
The model that I have laid out then allows me to create networks that overfit the XOR problem from randomized weights. For example, suppose that for , and , then for some initial random weights chosen from , I can plot the loss with respect to the total number of iterations.
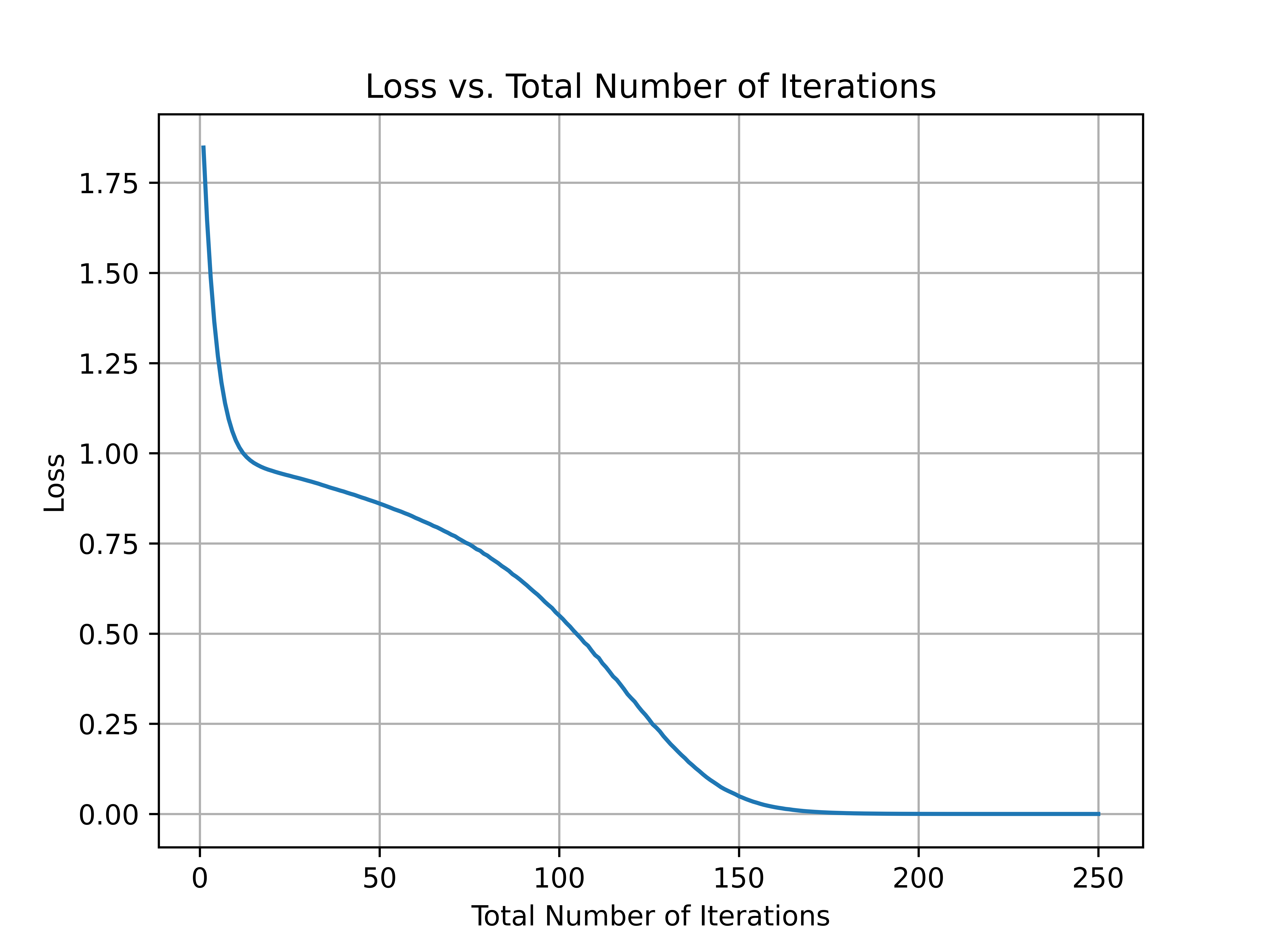 Unsurprisingly, increasing the total number of iterations decreases the loss function even more. In a future blog post, I will use this model to analyze more interesting problems.
Unsurprisingly, increasing the total number of iterations decreases the loss function even more. In a future blog post, I will use this model to analyze more interesting problems.
To see the python code that I wrote for this example, see here.